自动记账:Python+Beancount

自动记账:Python+Beancount
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/8462bc34.html
前言
你好,我是测试蔡坨坨。
这是复式记账系列的第四篇文章。在此之前,我们分别讨论了「一年之余,财富何方?」、「财富梳理:复式记账之道」以及「财富编织:Beancount复式记账指南」。分别解决了三个问题:“为什么要记账?”、“如何科学记账?”以及“复式记账工具Beancount的使用”。
相信对于看过前三篇文章并仍然选择继续阅读的你来说,Beancount记账应该是有一定吸引力的。
当我尝试使用Beancount手动记账一段时间后,虽然确实体会到了复式记账带来的财务清晰感,但由于手动记账过于单调乏味,逐渐感到疲倦。为了让记账这件事能够持续且高效地进行下去,实现自动记账势在必行。
在「财富编织:Beancount复式记账指南」文章末尾,也提出了自动记账的方案:
- 使用Python/Java等编程语言,实现账单(微信/支付宝账单)的自动导入和解析。
- 对于没有出现在账单中的交易,可以借助机器人(如Telegram、企业微信、钉钉)来实现
快速随时记账。
在本篇文章中,我们将着手实现第一个方案,即使用Python来实现账单的自动导入和解析。
当我将目光投向自动化复式记账领域,开始寻找相关轮子时,发现GitHub上确实有几个比较完善的工具。然而,它们的扩展性并不理想,有些只适用于支付宝账单,有些则只适用于微信账单。因此,我决定自己动手丰衣足食,实现一个扩展性较好、能够兼容支付宝、微信等账单的自动化复式记账轮子。
项目结构
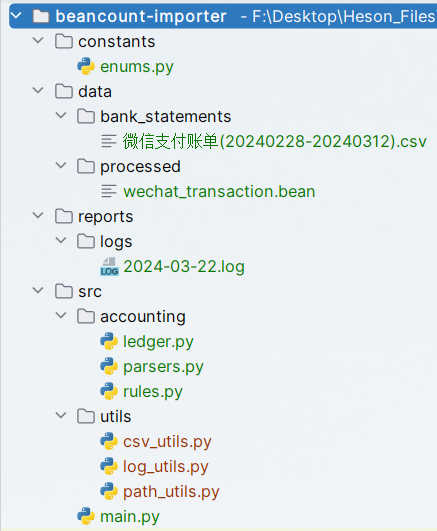
- constants:存放常量和枚举类
- enums.py:枚举类定义
- data:存放账单数据和其他数据文件
- bank_statements:存放账单记录数据
- processed:存放处理后的数据
- reports:存放报告文件
- logs:日志文件
- src:源代码目录
- accounting:核心会计功能模块
- ledger.py:复试记账模块
- rules.py:记账规则模块
- parsers.py:账单解析器模块
- utils:辅助工具函数
- csv_utils.py:CSV文件操作工具类
- log_utils.py:日志封装类
- path_utils.py:路径封装类
- main.py:项目入口文件,主函数
- accounting:核心会计功能模块
账单下载
微信账单
打开微信 - 我 - 服务 - 钱包 - 点击右上角的账单 - 再点右上角的常见问题 - 下载账单 - 用于个人对账
支付宝账单
打开支付宝 - 我的 - 账单 - 再点击左上角的更多 - 开具交易流水证明 - 用于个人对账 - 申请
读取CSV账单文件
在处理微信账单和支付宝账单之前,我们首先需要读取这些CSV文件。在读取CSV文件时,需确保文件的编码格式是UTF-8。因此,可以编写一个函数来检查文件的编码格式,当文件编码格式非UTF-8时将其转换为UTF-8编码。代码实现如下:
1 | # author: 测试蔡坨坨 |
定义枚举值
对于一些固定的常量,比如:供应商、账户、账单类型、交易类型,在enums.py中定义枚举类:
1 | # author: 测试蔡坨坨 |
账单解析
提取每条交易记录中的有用字段,例如:交易类型、交易对方、商品、收支情况、交易方式、交易状态。不同供应商的账单,字段所处的列可能不一样,我们可以利用前面定义的枚举类来指定每个字段在CSV文件中的列序号。然后,编写一个函数来解析每条记录,并根据指定的列序号提取字段的值。如下代码所示:
1 | # author: 测试蔡坨坨 |
微信账单样式:

支付宝账单样式:

解析规则
根据每条交易记录的有效字段定义匹配规则,且每个字段支持正则匹配,并确认每笔交易在记账中的借方和贷方。如下示例:
1 | class Rules: |
记账
定义好解析规则后,接着就是将账单中的每一笔交易与定义好的规则进行匹配,若命中规则便按照Beancount交易记录的格式进行记账,并输出到文件中。
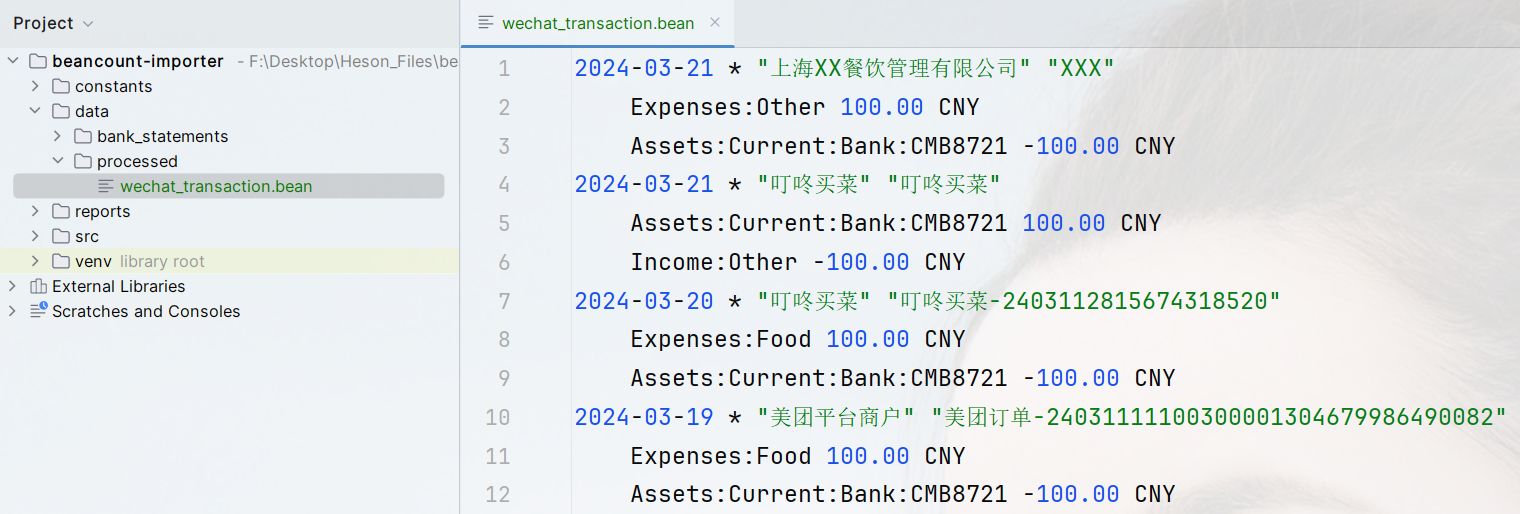
Beancount记账语法:
1 | 2024-01-01 * "滴滴打车" "打车到公司,银行卡支付" |
其中需要注意日期格式、交易方、交易备注、金额保留两位小数……
代码实现如下:
1 | # author: 测试蔡坨坨 |
主函数
运行main.py主函数,完成自动记账。
1 | # author: 测试蔡坨坨 |