什么是Context Engineering?一文读懂AI黑话之“上下文工程”

什么是Context Engineering?一文读懂AI黑话之“上下文工程”
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/fa542e75.html
你好,我是测试蔡坨坨。
自从ChatGPT横空出世以来,AI“黑话”层出不穷,什么RAG、Agent、MCP、A2A… 现在又来了个Context Engineering(翻译过来就是上下文工程)🤯
那什么是Context?Context Engineering又是什么?它解决了什么问题?以及如何解决问题?
是不是有点懵,别担心,这篇文章会一一给你解答。
准备好了吗?让我们开始这场"上下文"之旅!
🎯 什么是Context?从"黑盒子"说起
单纯从外部来看,大模型就像是一个函数,你给它输入,它就给你输出。
不过大模型的输入是有大小限制的,这个限制就叫做上下文窗口(Context Window)。
这里的Context指的就是模型输入。
1 | flowchart LR |
📝 Context到底是什么?
简单来说,Context就是模型在处理当前任务时能够"看到"的所有信息。它包括:
- ❓ 用户的问题
- 🌍 背景信息
- 📚 用户的历史对话
- 📖 相关资料
- 🔧 可用工具列表
- ⚡ 工具执行结果
🪟 Context Window:AI的"记忆容量"
而 Context Window 指的就是模型输入中最多能包含的token数量。
Token 可以理解为文本被拆分成的最小单位,可能是一个字、一个词、或者是一个标点符号。简单记住:
- 1个token ≈ 0.75个英文单词
- 1个token ≈ 1.5个汉字
举个栗子🌰:Gemini 2.5 Pro最多能输入100万token的上下文!一旦超过这个限制,前面的内容就会被无情丢弃,只保留最后的100万token。
💭 100万token大约相当于七本书的长度,也就是说Gemini 2.5 Pro可以一次性读完约七本书的内容,这个容量已经是非常惊人了。
看到这里你可能会想:“Context这么长,那我直接把所有资料都丢进去,让模型自己理解不就行了?”
🤖 理想很丰满,现实很骨感
📞 智能客服的"美好幻想"
假设你想做一个智能客服,希望它能回答用户关于公司产品的各种问题。
这个智能客服的核心就是一个大模型。大模型虽然很强,但直接问它关于你们公司产品的问题,它只能无奈地回答:“我不知道啊,我知道个锤子🤷♂️”。
于是你灵机一动:“没关系!我们有产品使用手册,直接丢给大模型就好了!”
你的想法是这样的:
- 产品手册几十页?丢进去!
- 几百页?也丢进去!
- 上千页?统统丢进去!
- 反正Context Window这么大,管它哪些内容相关不相关,让模型自己去理解!
这样做对吗?
答案是:不对! ❌
🚨 三个残酷的现实问题
事实并没有那么简单!在实际使用过程中,我们会遇到三个非常现实的问题:
1️⃣ 大多数模型的Context Window其实很"小气"
虽然Gemini 2.5 Pro有100万token,但看看其他模型:
| 模型 | Context Window | 备注 |
|---|---|---|
| Gemini 2.5 Pro | 100万 | 土豪级别 💰 |
| GPT-4 | 40万 | 还算够用 |
| Claude 4 | 20万 | 中规中矩 |
| Deepseek V3 | 12.8万 | 有点紧张 😅 |
要命的是,有时候为了节省成本,我们经常使用一些"小模型",它们的Context Window可能只有几万token。连一个完整的产品使用手册都装不下!
2️⃣ 信息太杂乱,AI也会"选择困难症"
即使你的模型有超大Context Window,也不能把所有资料不加筛选地全部丢给它!
想象一下:你让一个人在一堆杂乱无章的文件中找答案,他会怎么样?
- 😵💫 被信息淹没
- 🤔 分不清重点
- 😅 给出模糊的回答
AI模型也是一样的!杂乱、冗余、矛盾的信息会让它"选择困难",最终输出含糊其辞的回答。
💡 关键insight:与其把所有信息都塞进去,不如精心设计和组织,确保模型看到的是准确、有结构、重点突出的内容。
3️⃣ 输入越多,钱包越瘪 💸
这是最现实的问题:大多数模型厂商都是按token计费!
如果不加控制地塞入大量上下文内容,即使效果还行,也可能带来不必要的开销。
优化输入 = 优化成本
所以我们看到直接把资料丢给大模型的思路是行不通的,这里存在很多的问题。那我们该如何解决它们呢?
这就引出Context Engineering了!🎉
🔧 什么是Context Engineering?
📖 定义解析
Context Engineering翻译成中文就是上下文工程。从字面上来看,Context Engineering似乎就是针对Context所做的一些技术。
回想一下Context的含义:
- Context = 给模型的输入
- 那么,Context Engineering = 对模型输入做优化
🎯 核心理念
Context Engineering关注的不是怎么训练模型,而是怎么精心设计给模型的输入内容。
它要让模型在有限的Context Window里面尽可能地:
- 🎯 理解更准
- 💬 答得更好
- 💰 花得更少
💭 核心思想:不改变模型的结构,只改变模型能"看到"什么。就像给AI戴上了一副"智能眼镜"👓
1 | flowchart TD |
🚀 为什么Context Engineering突然火了?
其实Context这个概念一直都存在,但是Context Engineering却是最近一段时间才火起来。
🎯 两大推动力
1️⃣ 模型足够强大了!💪
现在的模型已足够强大,对比一年前的模型,简直是天壤之别!
对于现在的模型来说,你只要给到它:
- ✅ 足够精细的要求
- ✅ 足够完整的相关资料
模型就能给出非常准确有用的回答!
💭 关键insight:在大部分情况下,如果模型的回答不能让你满意,这并不是因为模型不够强大,而是因为你没有给到模型足够清晰、完整的信息。而这一点,正是Context Engineering要解决的问题!
2️⃣ Agent的兴起!🤖
Agent是一种把大模型和工具结合起来,让模型能够独立感知环境、影响环境,从而解决用户问题的技术。
Agent运行时会产生大量信息:
- 🔧 可用工具信息
- ⚡ 工具执行结果
- 📝 运行历史记录
使用多少次工具 → 就有多少个工具执行结果 → Agent运行时间长了 → 这些结果占满整个Context Window → 影响模型后续回答效果
🎯 这就是为什么:Agent兴起之后,Context Engineering的话题也随之火了起来!因为Context的管理效果直接影响到Agent的执行结果。
🛠️ Context Engineering的四大绝招
在了解了Context Engineering兴起的原因之后,接下来我们就看一下它具体的实现方法。
Context Engineering并不是某项单一的技术,而是多种技术组成的方法体系。
🎯 四大核心步骤
Context Engineering分为四个步骤:
- 💾 保存Context
- 🎯 选择Context
- 🗜️ 压缩Context
- 🔒 隔离Context
让我们逐一击破!💪
💾 第一招:保存Context
保存Context就是说我们把Context做个筛选总结并找个地方保存起来,比如内存/硬盘之类的地方,在模型需要的时候再发给模型。
🌟 经典案例:ChatGPT的记忆功能
这里一个比较典型的例子就是ChatGPT的记忆功能。比如我在一次对话中跟ChatGPT说:
我的名字是蔡坨坨,我有一个公众号叫测试蔡坨坨,在这个公众号里我分享过软件测试、Python测试开发、AI、RAG、GraphRAG、MCP等相关的内容,记住这些!

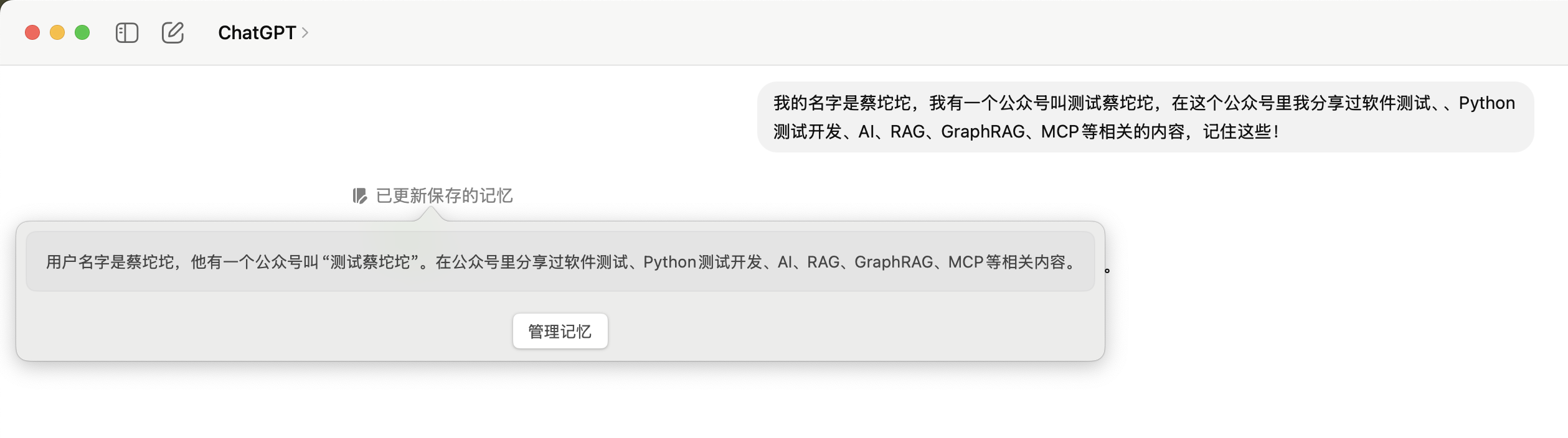
注意到这个"已更新保存的记忆",这代表ChatGPT把这段内容存入到它的记忆库里面去了!🧠
🎯 核心价值:这个保存的动作是Context Engineering的第一步,它解决了信息持久化的问题。就像给AI装了个"外置硬盘"💾
但光存下来还不够!ChatGPT的记忆库是可以存放很多条记录的,那在未来的工作中,ChatGPT是如何从这个庞大的记忆库里面精准的找到它想要的信息呢?🤔
🎯 第二招:选择Context
这就引出了Context Engineering的第二个步骤:选择Context!
选择Context就是从海量的信息中选择出一部分与用户问题最相关的内容,并且把它们放在模型的Context里面。
🎯 关键insight:一个好的选择策略是整个系统高效准确运行的保障!就像一个聪明的图书管理员📚
选择又分为静态选择和动态选择:
📌 静态选择:AI的"基本法"
静态选择就是把一些永远重要、必须要遵守的信息在每一次请求时全部放到Context里面。
它就像是给AI"焊在脑子里"的系统指令或者核心原则🧠⚡
经典例子:
- 🔧 Cursor的rules文件
- 📝 Claude Code的CLAUDE.md文件
- 📋 Trae的user_rules.md、project_rules.md文件
这些文件指定了:
- 📊 当前项目的信息
- 📏 编码时需要遵守的规范
- 🎯 AI行为的核心原则
💡 策略要点:这些信息至关重要,无论用户问什么,都必须在场!对于这类短小但至关重要的信息,最有效的策略就是全部都要,只要确保它们加起来不会撑爆Context Window就行。
🎯 动态选择:智能图书管理员
说完了静态选择,接下来我们看一下更强大、也更为常见的动态选择。
动态选择是指选择与用户问题最相关的内容,并且把它放入Context中。它不是所有的东西都塞进去,而是像一个聪明的图书管理员📚,为你精准地找到需要的那几页。
经典案例:
- 🧠 ChatGPT从记忆库中挑选与用户问题最相关的记忆。
- 🔧 从数十个甚至数百个工具中挑选最相关的3个工具放入Context,这也是一种动态选择。
🎯 最著名的实现方式:RAG(检索增强生成),可参考往期文章「搭建一个本地 AI 知识库需要用到哪些技术栈?」
🗜️ 第三招:压缩Context
压缩Context是指在保留关键信息的前提下,减少Context的长度。
💡 核心理念:用最少的字符,传达最多的信息!就像把一本厚书压缩成精华版📖➡️📄
🛠️ 常见压缩方式
压缩Context有很多种方式:
- 📝 总结:把长对话浓缩成几句话
- 🔑 关键词提取:提炼文档核心要点
- 🔄 信息去重:删除重复内容
- 🎯 结构化提取:保留关键数据结构
🎯 实战案例:Agent的历史消息压缩
Agent在运行时会在Context中积累大量的历史消息,一般来说,这些历史消息中最占空间的便是模型的输出文本和工具执行结果两类数据。
如果不做处理的话,这些消息便会迅速挤满Context的全部空间,从而影响模型的后续回答效果。
经典解决方案:Claude Code的auto-compact程序
- 🔄 对以往的Context做压缩
- 📝 总结之前的内容
- 🗑️ 把原来的内容扔掉
- 📊 总结后,Context Window的使用量就会降下来
- ⚙️ 用户甚至可以在Claude.md里面指定压缩方案
🎯 压缩的好处:让我们在有限的Context Window中放入更多信息,从而提高模型性能!
🔒 第四招:隔离Context
说完压缩Context,下面我们就来说说最后一个策略:隔离Context。
隔离Context是指把不同类型的信息分别放在不同的Context中,从而避免信息之间的相互干扰🚧
💡 核心思想:让不同类型的信息"各司其职",避免"串台"现象!就像把不同的菜分装在不同的盘子里🍽️
🌟 经典案例:Anthropic的Multi-Agent系统
隔离Context最典型的应用场景就是Multi-Agent系统。不同模块之间的Context是互相隔离的,互不干扰。
原文:「How we built our multi-agent research system」
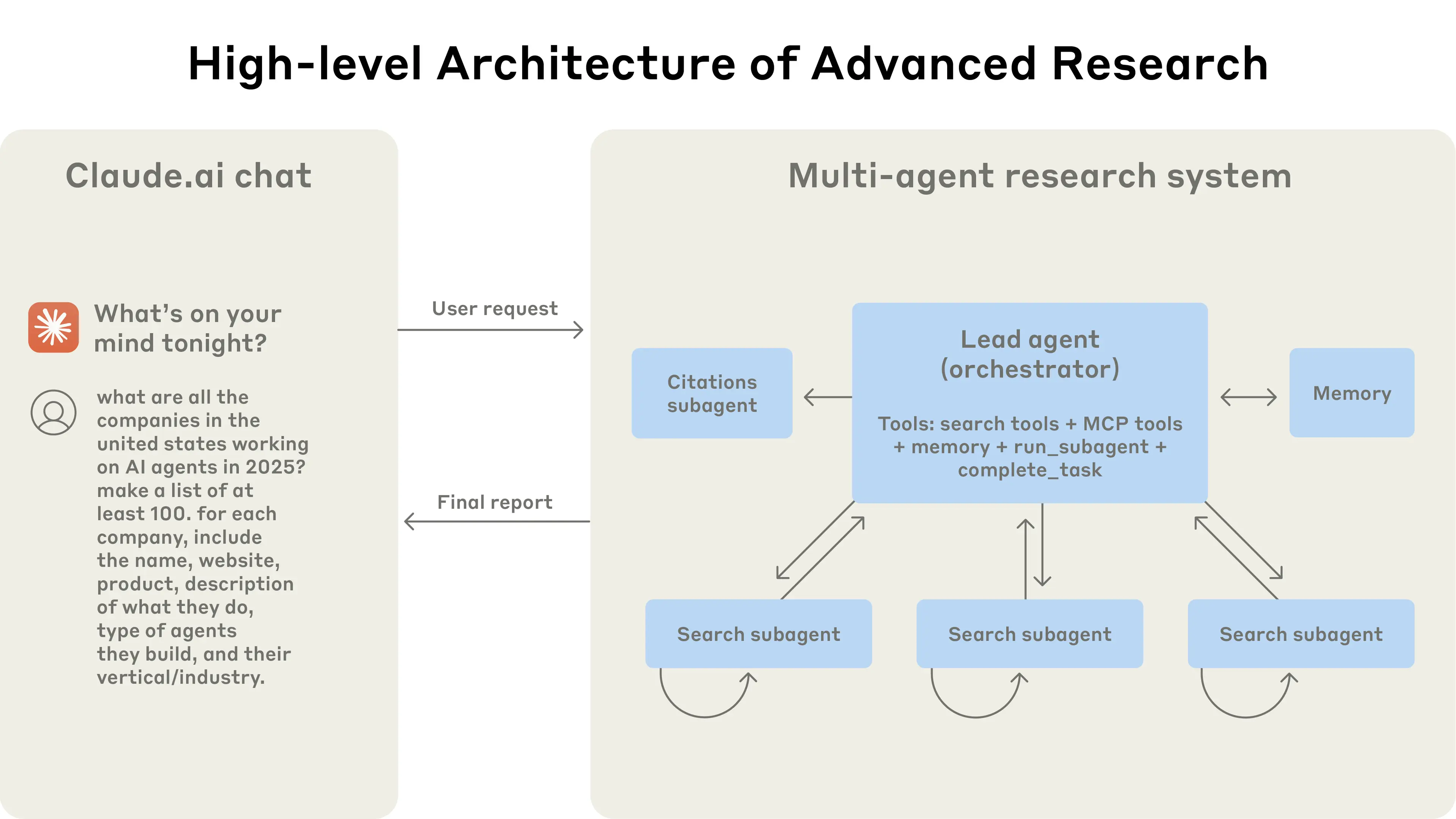
在Multi-Agent系统中:
- 🎯 Lead Agent:系统的总指挥官,负责任务下发和归纳总结。
- 🔍 Subagent:各司其职的专业助手
工作流程:
- 👤 用户请求 → Lead Agent(用户请求会先打到Lead Agent)
- 📋 Lead Agent分解任务 → 各个Subagent(在接收到用户请求之后,Lead Agent便会把用户的问题拆解成多个task,并下发到其他的Agent系统里,Anthropic把这些Agent称为Subagent)
- 🔍 搜索内部知识库的Subagent → 获取内部信息
- 🌐 联网搜索的Subagent → 获取外部信息
- 📊 Lead Agent汇总所有结果 → 生成最终报告
Context隔离体现:
- 🔍 每个Subagent都有专属的Context
- 🚧 各Context之间互不干扰,职责清晰
💡 这就是隔离Context的典型例子:不同系统拥有不同Context,各司其职,互不干扰!
📋 总结
Context Engineering 的关键在于“让模型看到对当前任务最必要且组织良好的信息”。
通过先保存与结构化知识,再用静态/动态策略精准选择,配合总结与关键词等方式压缩,并在多主体/多任务中做好隔离,可在有限的上下文窗口内显著提升回答质量,降低冗余与成本。






