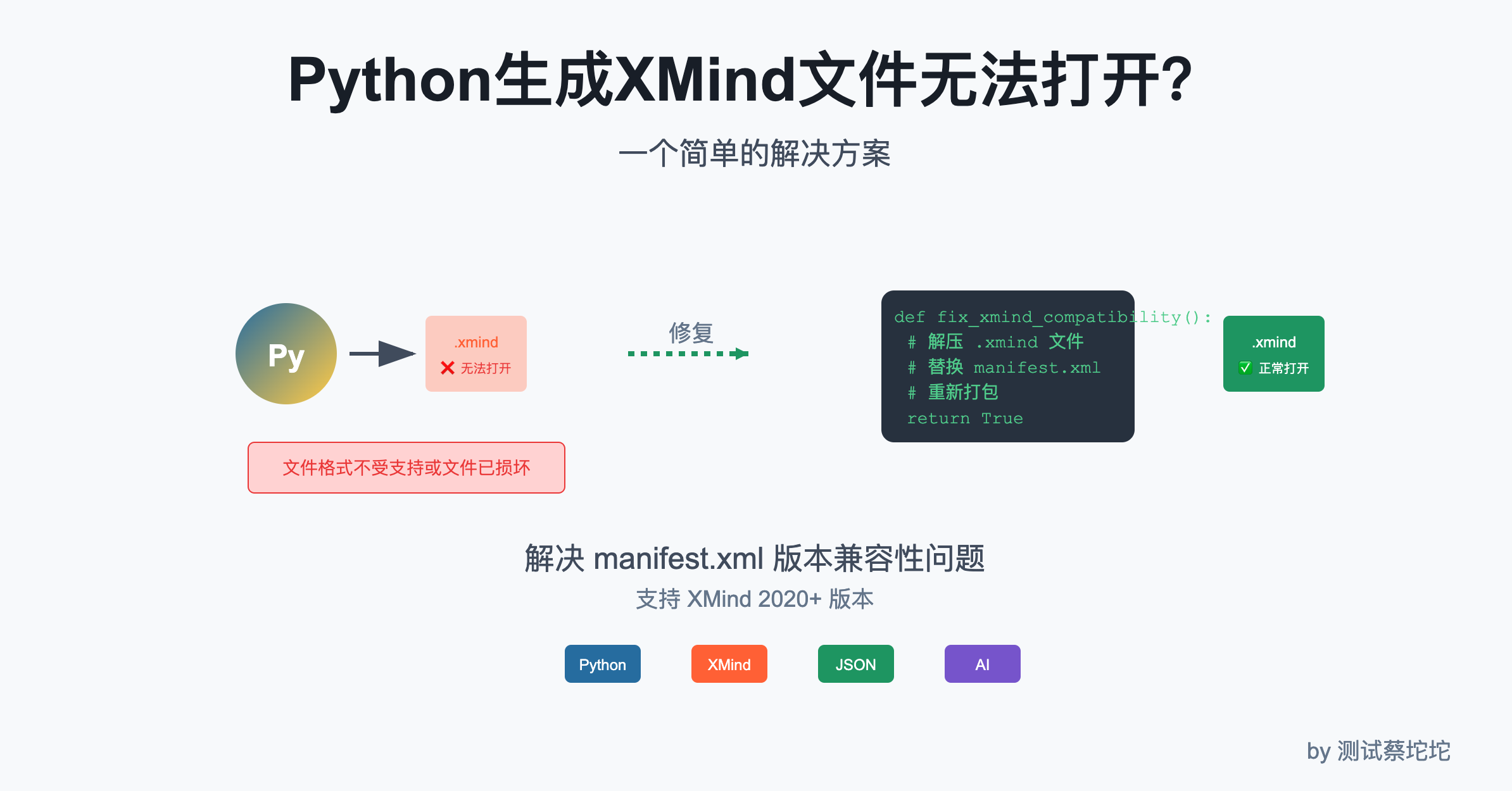
AI解决Python生成XMind文件无法打开
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/f910170a.html

1 问题背景
你好,我是测试蔡坨坨。
最近在尝试使用AI生成测试用例,为了让用例可视化效果最佳,想了一个简单的实现思路:先让AI生成JSON格式的测试用例,再使用Python脚本将JSON转成XMind文件,进一步可以将其包装成MCP工具以供大模型使用,然而在实践过程中发现……
生成的.xmind文件在XMind 2020+版本里死活打不开,报错“not a valid XMind File”:
简单分析一下:
- 生成的文件大小正常,排除代码方面的问题
- 使用老版本XMind 8可以打开,但新版本就不行
- XMind 8 和 XMind 2020+ 的区别是什么?
2 排查过程
2.1 XMind 文件结构
顺着上面的分析,在 XMind 8 版本中可以打开,而在 XMind 2020+ 版本中无法打开,基本可以确认是版本兼容性问题,也就是说我们使用Python的xmind库生成的XMind文件是 XMind 8 版本,所以只要我们知道两个版本之间的差异,并通过某种方式将 XMind 8 版本的文件转成兼容高版本的不就OK了。
那么问题来了,某种什么方式呢?
比如:先用 XMind 8 打开用 Python 生成的 XMind 文件,再另存为,这时就能兼容高版本了。
显然这种做法有点笨,不仅不能自动化,还得装两个版本的XMind,毕竟大部分人用的都是 XMind 2020+ 版本。
所以有没有更智能的方式呢?
有的兄弟!
回到前面的问题,要想实现两个版本的 XMind 文件转换,我们得先知道它两有什么区别。
众所周知,XMind文件其实就是一个zip压缩包,里面包含了XML文件和其他资源。
试着解压看看,使用下面这两条命令:
1
| cp xmind测试用例_1754818615.xmind test_cases.zip
|
1
| unzip test_cases.zip -d extracted/
|
XMind 8:
XMind 2020+:
解压后发现里面有这些文件:
- content.xml:主要内容
- styles.xml:样式定义
- comments.xml:评论
//META-INF/manifest.xml:文件清单,差别就在这个文件,XMind 8 没有,高版本有
2.2 解决思路
既然知道了问题所在,解决起来就简单了,在生成XMind文件之后,再添加//META-INF/manifest.xml文件,这样就能解决版本兼容问题了。
3 代码实现
3.1 创建manifest.xml文件
1
2
3
4
5
6
7
8
9
10
11
| <?xml version="1.0" encoding="UTF-8" standalone="no"?>
<manifest xmlns="urn:xmind:xmap:xmlns:manifest:1.0">
<file-entry full-path="comments.xml" media-type=""/>
<file-entry full-path="content.xml" media-type="text/xml"/>
<file-entry full-path="markers/" media-type=""/>
<file-entry full-path="markers/markerSheet.xml" media-type=""/>
<file-entry full-path="META-INF/" media-type=""/>
<file-entry full-path="META-INF/manifest.xml" media-type="text/xml"/>
<file-entry full-path="meta.xml" media-type="text/xml"/>
<file-entry full-path="styles.xml" media-type=""/>
</manifest>
|
3.2 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
| def fix_xmind_compatibility(self, xmind_path: str, manifest_path: str = None) -> bool:
"""
修复 XMind 版本兼容性问题
**场景**: 生成的xmind文件只能在 XMind 8 中打开 XMind 2020+ 中无法打开
**解决方案**: 通过添加 manifest.xml 文件来修复兼容性问题
流程:
1. 将 .xmind 文件重命名为 .zip
2. 解压 .zip 文件
3. 添加 META-INF/manifest.xml 文件
4. 重新压缩为 .zip
5. 重命名回 .xmind
Args:
xmind_path: XMind 文件路径
manifest_path: manifest.xml 文件路径,如果为 None 则使用默认路径
Returns:
bool: 处理是否成功
"""
if not os.path.exists(xmind_path):
self.log.error(f"XMind 文件不存在: {xmind_path}")
return False
if manifest_path is None:
manifest_path = os.path.join(os.path.dirname(__file__), "manifest.xml")
if not os.path.exists(manifest_path):
self.log.error(f"manifest.xml 文件不存在: {manifest_path}")
self.log.info("请确保 manifest.xml 文件存在,或提供正确的文件路径")
return False
folder = os.path.dirname(xmind_path)
filename = os.path.basename(xmind_path)
name_without_ext = os.path.splitext(filename)[0]
temp_zip_path = os.path.join(folder, f"{name_without_ext}.zip")
temp_extract_dir = os.path.join(folder, f"{name_without_ext}_temp")
original_cwd = os.getcwd()
try:
self.log.info(f"开始处理 XMind 文件: {xmind_path}")
if os.path.exists(temp_zip_path):
os.remove(temp_zip_path)
shutil.copy2(xmind_path, temp_zip_path)
self.log.debug(f"创建临时 ZIP 文件: {temp_zip_path}")
if os.path.exists(temp_extract_dir):
shutil.rmtree(temp_extract_dir)
if not self.extract(temp_extract_dir, temp_zip_path):
self.log.error("解压 XMind 文件失败")
return False
meta_inf_dir = os.path.join(temp_extract_dir, "META-INF")
os.makedirs(meta_inf_dir, exist_ok=True)
target_manifest_path = os.path.join(meta_inf_dir, "manifest.xml")
shutil.copy2(manifest_path, target_manifest_path)
self.log.debug(f"替换 manifest.xml: {manifest_path} -> {target_manifest_path}")
os.remove(temp_zip_path)
archive_path = shutil.make_archive(
os.path.join(folder, name_without_ext),
'zip',
temp_extract_dir
)
self.log.debug(f"重新压缩完成: {archive_path}")
shutil.move(archive_path, xmind_path)
self.log.info(f"XMind 文件处理完成: {xmind_path}")
return True
except Exception as e:
self.log.error(f"处理 XMind 文件时发生错误: {e}")
return False
finally:
try:
if os.path.exists(temp_zip_path):
os.remove(temp_zip_path)
if os.path.exists(temp_extract_dir):
shutil.rmtree(temp_extract_dir)
self.log.debug("临时文件清理完成")
except Exception as e:
self.log.warning(f"清理临时文件时发生错误: {e}")
os.chdir(original_cwd)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| def extract(self, extract_to_path: str, archive_path: str, mode: str = "zip") -> bool:
"""
解压缩文件并处理中文文件名乱码问题
Args:
extract_to_path: 解压目标目录
archive_path: 压缩文件路径
mode: 压缩格式 ("zip" 或 "rar")
Returns:
bool: 解压是否成功
"""
if not os.path.exists(archive_path):
self.log.error(f"压缩文件不存在: {archive_path}")
return False
os.makedirs(extract_to_path, exist_ok=True)
self.log.info(f"开始解压 {mode} 文件: {archive_path} -> {extract_to_path}")
try:
if mode == 'zip':
archive_file = zipfile.ZipFile(archive_path, "r")
elif mode == 'rar':
archive_file = rarfile.RarFile(archive_path, "r")
else:
self.log.error(f"不支持的压缩格式: {mode}")
return False
with archive_file:
extracted_count = 0
for file_info in archive_file.infolist():
original_filename = file_info.filename
decoded_filename = self._decode_filename(original_filename)
full_path = os.path.join(extract_to_path, decoded_filename)
if decoded_filename.endswith("/") or decoded_filename.endswith("\\"):
os.makedirs(full_path, exist_ok=True)
self.log.debug(f"创建目录: {full_path}")
else:
parent_dir = os.path.dirname(full_path)
if parent_dir:
os.makedirs(parent_dir, exist_ok=True)
try:
with open(full_path, "wb") as output_file:
output_file.write(archive_file.read(original_filename))
extracted_count += 1
self.log.debug(f"解压文件: {decoded_filename}")
except Exception as e:
self.log.warning(f"解压文件失败 {decoded_filename}: {e}")
continue
self.log.info(f"解压完成,共解压 {extracted_count} 个文件")
return True
except Exception as e:
self.log.error(f"解压过程中发生错误: {e}")
return False
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| def _decode_filename(self, filename: str) -> str:
"""
尝试多种编码方式解码文件名,解决中文乱码问题
Args:
filename: 原始文件名
Returns:
str: 解码后的文件名
"""
encoding_attempts = [
("utf-8", "UTF-8编码"),
("gbk", "GBK编码"),
("gb2312", "GB2312编码"),
]
for encoding, desc in encoding_attempts:
try:
decoded_name = filename.encode('cp437').decode(encoding)
self.log.info(f'文件名解码成功 ({desc}): {filename} -> {decoded_name}')
return decoded_name
except (UnicodeDecodeError, UnicodeEncodeError):
continue
print(f"文件名解码失败,使用原始文件名: {filename}")
return filename
|