
Postman实现WebUI自动化测试

Postman实现WebUI自动化测试
蔡坨坨前言
说到Web UI自动化测试,就不得不提到Selenium,作为一个经典的UI自动化测试工具,距今已有20年,经历了4个大版本的迭代。
对于自动化工具,大多数研究的都是工具怎么用,更加关注应用层面的东西,怎么去定位元素、操作元素、模拟请求、解析响应、断言、怎么去用pytest、unittest ……
对于Selenium来说,也只是一个基本的应用包,所以这里不会介绍Selenium如何使用,主要讲解其工作原理。
Selenium版本
2006年,Selenium 1.0发布
Selenium 1.0包含Selenium IDE(浏览器插件,主要做的是基于火狐浏览器的脚本录制和回放功能。可以帮助我们录制并生成脚本,对于不会代码的同学来说,它是一个非常好的开始,但现在基本被淘汰了)、Selenium Grid(分布式,将一套脚本分发到不同的机器上执行,功能非常强大,现在还在使用)、Selenium RC(脚本控制浏览器实现自动化的原理,但是它的实现并不完善,到Selenium 2.0时代被WebDriver替代)。
同年,Google工程师Simon Stewart发起了一个名为WebDriver的项目,它也是一个自动化测试工具,彼时刚刚起步,后来它也成为Selenium的竞品之一。
2009年,Selenium 2.0发布
2009年,在Google测试自动化会议上,Selenium和WebDriver两个团队的开发人员在沟通后决定合并这两个项目,新项目被命名为Selenium Web Driver,也就是Selenium 2.0。很多人接触Selenium,也是从Selenium 2.0开始的。
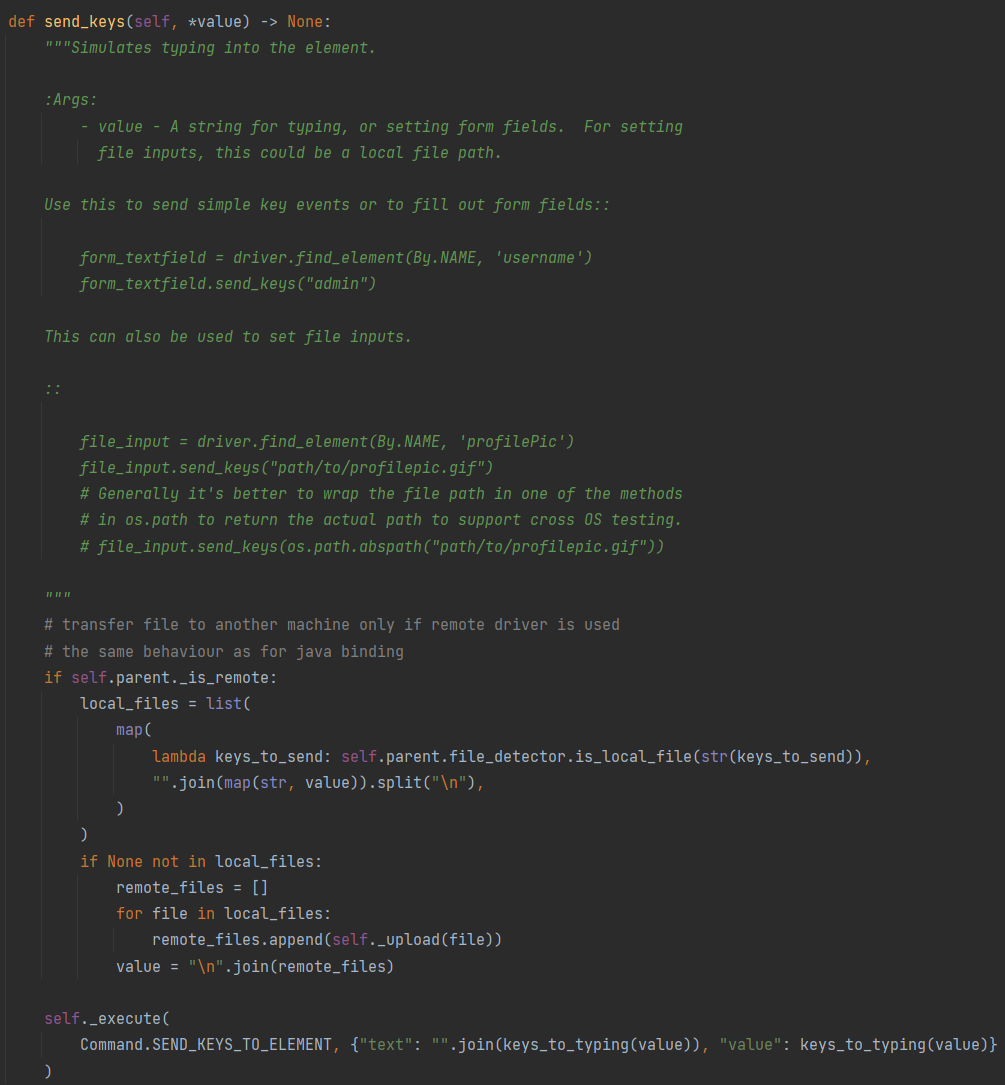
WebDriver的实现原理其实就是在
Web浏览器和我们的脚本之间有一个WebDriver,通过WebDriver协议去驱动并操作浏览器。WebDriver的作者是这样解释二者合并的原因:“一方面WebDriver解决了Selenium存在的缺点(例如:可以绕过JavaScript沙箱,WebDriver有出色的API),另一方面Selenium解决了WebDriver存在的问题,还有就是Selenium主要贡献者和WebDriver的作者都认为合并项目是为用户提供最优秀框架的最佳途径。”
Selenium 2.x(WebDriver)真正兴起是在2014年开始,到2016年左右成为Web自动化最热门的框架。几乎谈及Web自动化,那就是Selenium。它不仅在Web自动化测试领域很火,在爬虫领域也是非常热门。
2016年,Selenium 3.0发布
这个版本并没有引入新的工具,主要是加强了对浏览器的支持。
完全移除了Selenium RC;WebDriver暴露一个供浏览器接入的API,通过各浏览器厂商提供的Driver来接入;将内置的Firefox Driver剔除;支持Firefox通过GRCKO Driver来接入Selenium;通过Apple提供的Safari Driver来接入Safari;通过Edge Driver支持IE接入。
所以,3.x和2.x其实没有太大的区别。
2021年,Selenium 4.0发布
在Selenium 3.x中,与浏览器的通信基于JSON-wire协议,因此Selenium需要对API进行编解码。而Selenium 4遵循W3C标准协议,Driver与浏览器之间通信的标准化使得它们可以直接通信。
将Selenium3中不常用和不好用的做了相关的减法和优化。最明显的就是一系列的 find_element_by_xx 方法 find_element_by_id、find_element_by_name、find_element_by_class_name 等都被整合成为了一个方法 find_element,并且通过 By.method 来选择你的查找元素方法。(Selenium 4 有哪些不一样?)
Selenium+WebDriver 原理
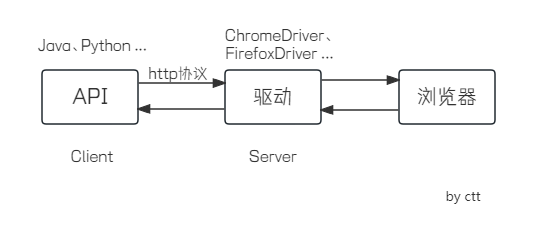
- 运行脚本,启动浏览器后,webdriver会将浏览器绑定到特定的端口,作为webdriver的remote server 远程服务端;
- 而client 客户端(测试脚本,Python、Java…)会借助CommandExecutor创建sessionId,发送http请求给remote server;
- remote server收到http请求后,调用webdriver完成操作,并将http响应结果返回给client。
所以,本质上是调用http请求的过程,因此也就可以理解为什么可以使用Postman实现UI自动化测试。
Postman实现UI自动化测试
以上我们知道了Selenium的底层原理其实就是调用http请求的过程,那么我们要想调用接口就需要知道接口信息,包括请求方式、请求地址、请求参数、请求格式等。
这些接口信息,我们可以通过对源码的分析得到。
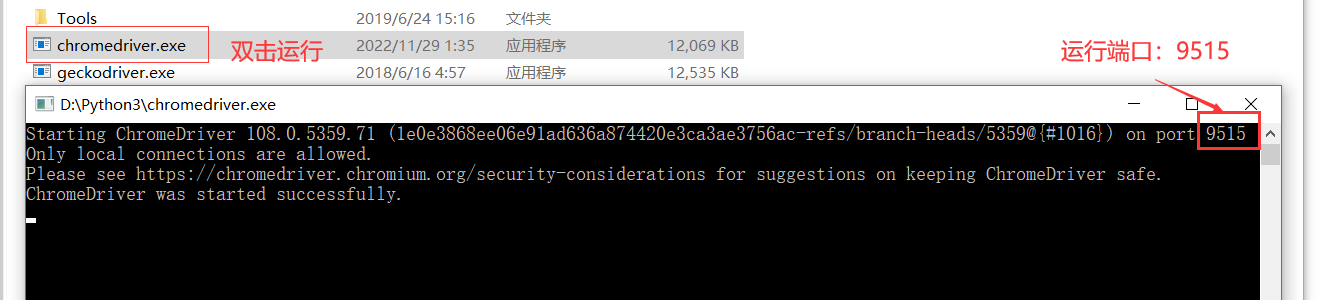
运行chromedriver.exe
Selenium脚本:
1 | from selenium import webdriver |
执行上述代码,程序会打开Chrome浏览器。(前提:已经正确配置了Chrome驱动和对应的版本)
那么,Selenium是如何实现这一过程的呢?
源码分析:
D:\Python3\Lib\site-packages\selenium\webdriver\chrome\webdriver.py


我们可以看到它执行了一个cmd命令,这个命令主要是启动chromedriver.exe浏览器驱动,我们每次执行脚本前,程序会自动帮我们启动浏览器驱动。
由于我们跳过了代码脚本,因此需要手动启动浏览器驱动。
地址及端口号:127.0.0.1:9515
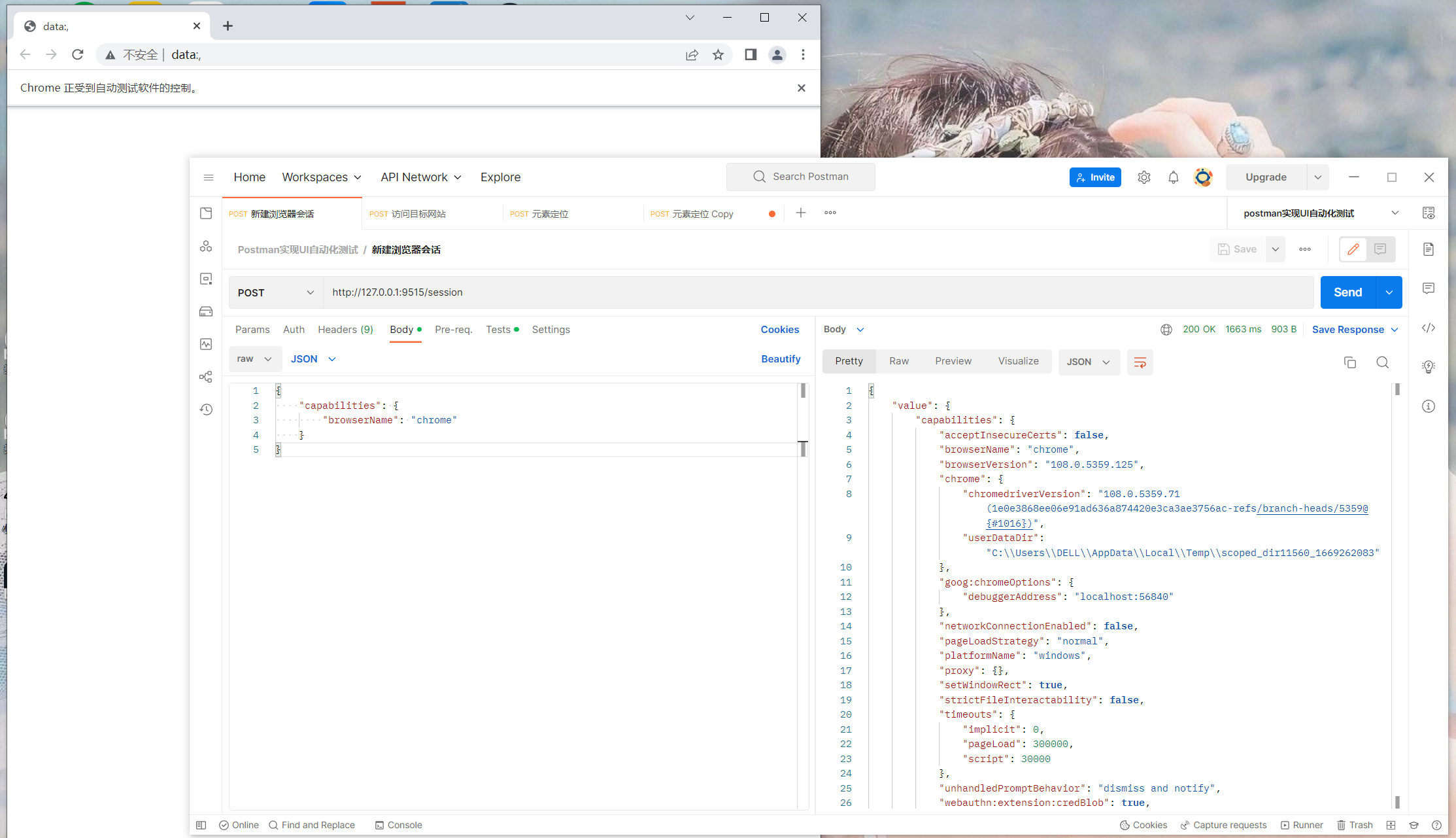
新建浏览器会话
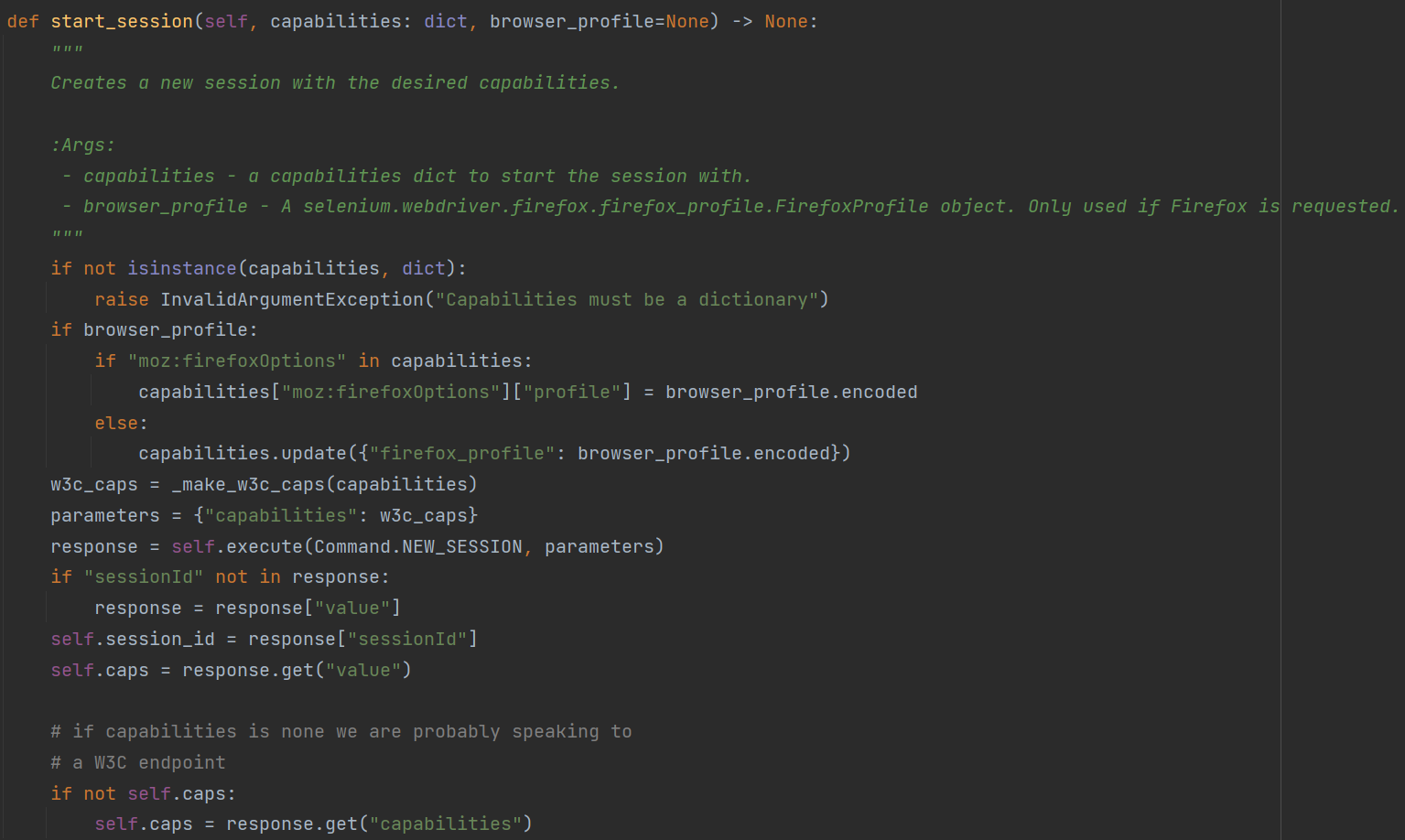
D:\Python3\Lib\site-packages\selenium\webdriver\remote\webdriver.py
继续查看源码,这里有一行重要的代码:

start_session()这个方法是向地址http://127.0.0.1:9515/session发送了一个post请求,参数是JSON格式,然后返回一个特定的响应信息给程序,主要就是新建了一个sessionId。


接口信息:
1 | url: /session |
请求参数:
1 | { |
调用接口:
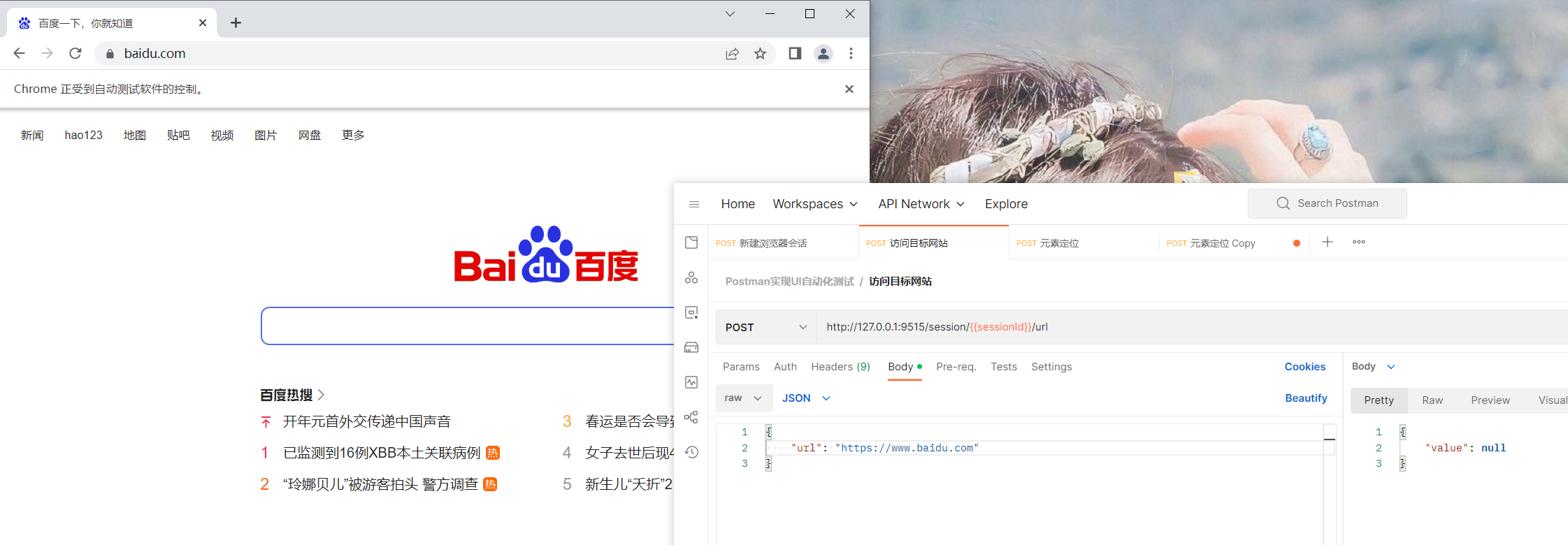
访问目标网站
Selenium脚本:
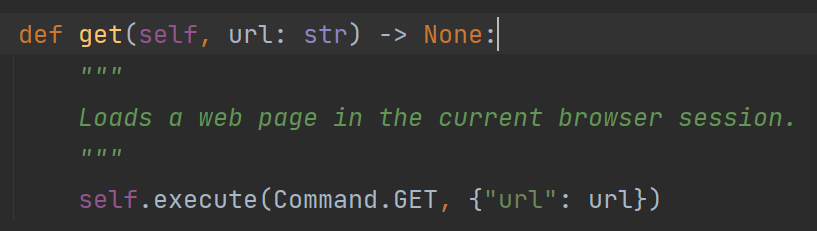
1 | driver.get("https://www.baidu.com") |
执行以上代码,可以访问目标网站。
源码分析:
D:\Python3\Lib\site-packages\selenium\webdriver\remote\remote_connection.py
在RemoteConnection这个类中,定义了所有selenium操作需要的接口地址(这些接口地址全部封装在浏览器驱动程序中)。
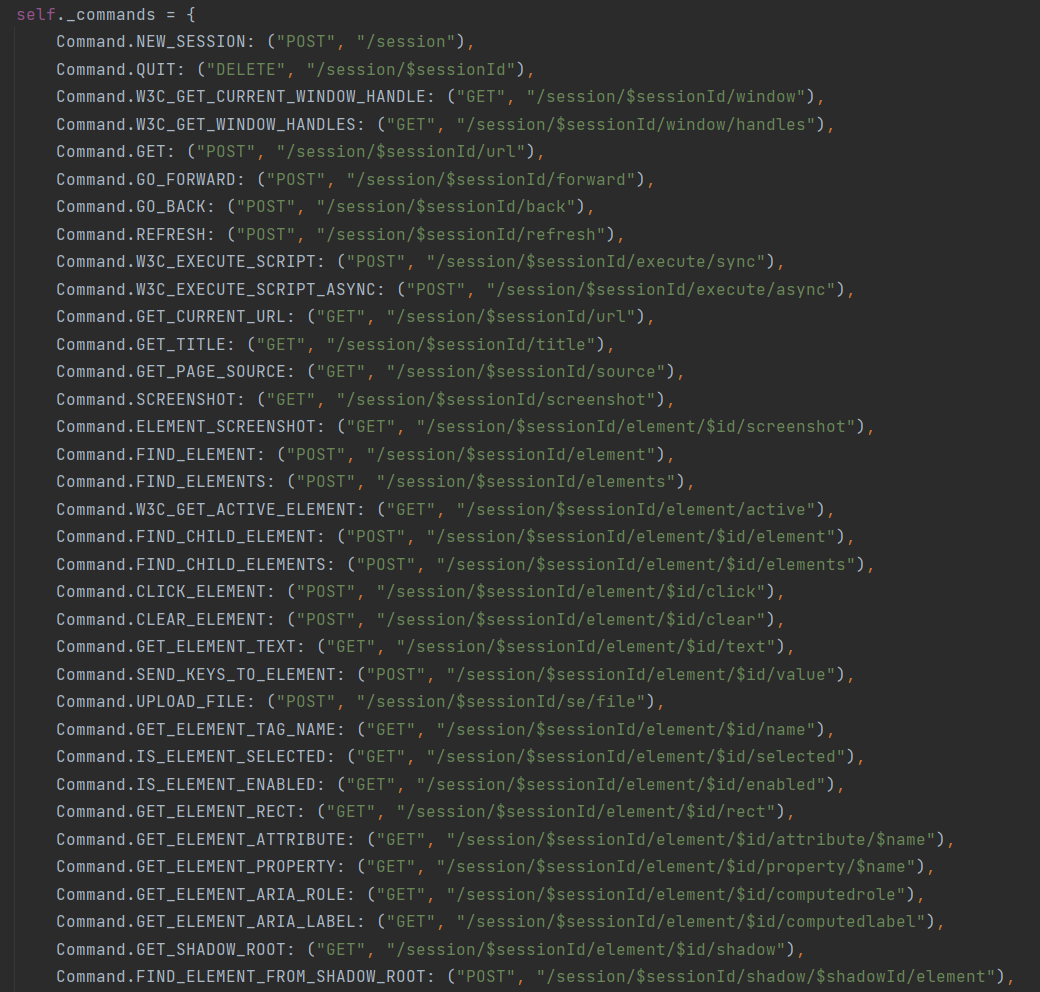
其中Command.GET: ("POST", "/session/$sessionId/url")这个地址就是实现访问一个网站的URL。

紧接着,可以看到主要是通过execute()方法调用_request()方法通过urllib3标准库向服务器发送对应操作请求地址,进而实现浏览器各种操作。
而打开浏览器和操作浏览器实现各种动作是通过上一步新建浏览器会话返回的sessionId实现的关联。你也会发现后面操作的各种接口地址中都存在一个$sessionId,以达到能够在同一个浏览器中做操作。


接口信息:
1 | url: /session/$sessionId/url |
请求参数:
1 | { |
调用接口:
窗口最大化
Selenium脚本:
1 | driver.maximize_window() |
源码分析:

接口信息:
1 | url: /session/$sessionId/window/maximize |
调用接口:

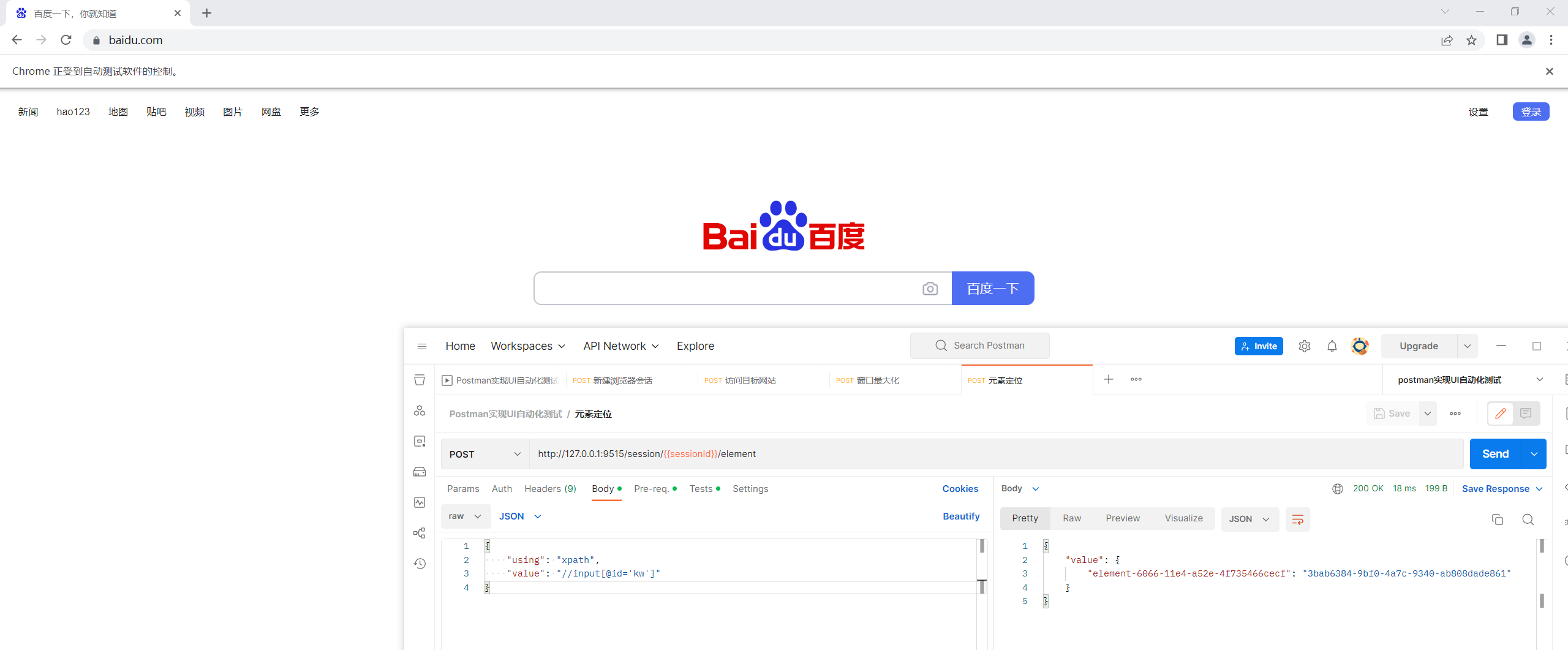
元素定位
Selenium脚本:
1 | driver.find_element(By.XPATH, "//input[@id='kw']") |
源码分析:


接口信息:
1 | url: /session/$sessionId/element |
请求参数:
1 | { |
接口调用:
输入文本
Selenium脚本:
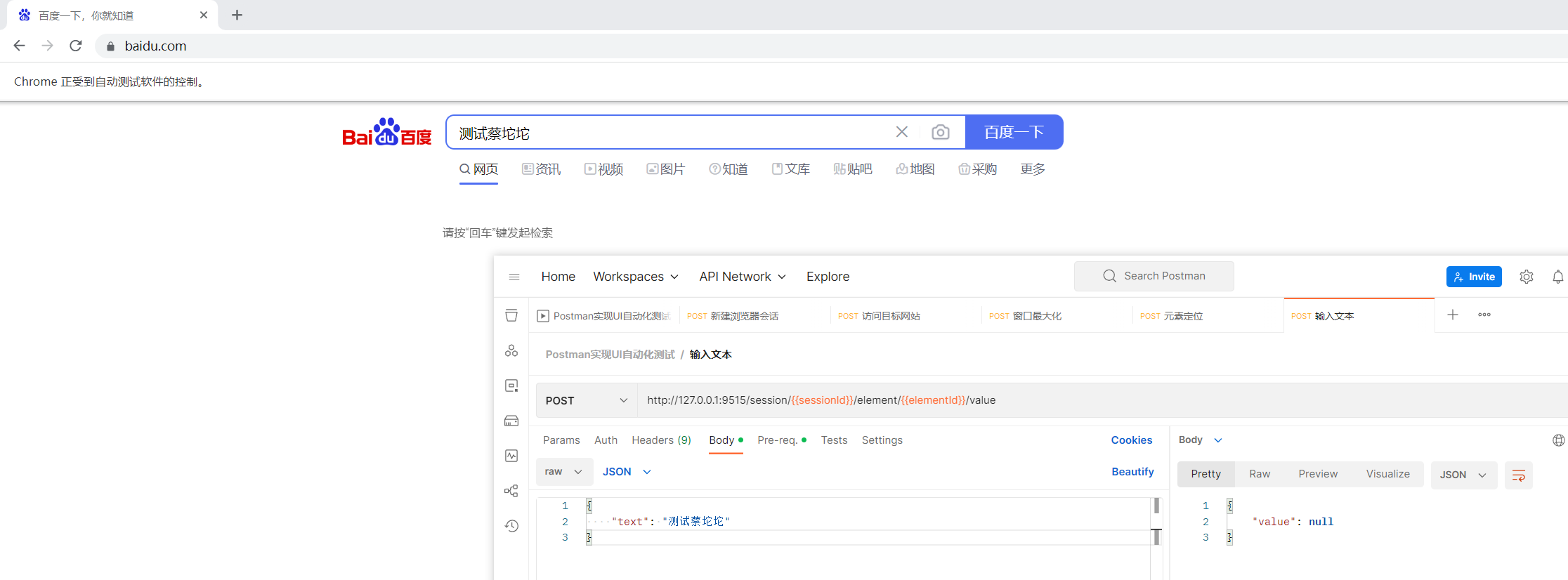
1 | driver.find_element(By.XPATH, '//input[@type="text"]').send_keys("测试蔡坨坨") |
源码分析:

接口信息:
1 | url: /session/$sessionId/element/$id/value |
请求参数:
1 | { |
接口调用:
点击元素
Selenium脚本:
1 | driver.find_element(By.XPATH, "//input[@id='su']").click() |
源码分析:

接口信息:
1 | url: /session/$sessionId/element/$id/click |
接口调用:

关闭浏览器
Selenium脚本:
1 | driver.quit() |
源码分析:

接口信息:
1 | url: /session/$sessionId |
接口调用:







