MySQL不要再用utf8了

MySQL不要再用utf8了
蔡坨坨转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/6719361d.html
你好,我是测试蔡坨坨。
前些日碰到一个因MySQL数据库编码问题导致的Bug,在此记录,供小伙伴参考。
Bug回顾
原本是一句再普通不过的INSERT语句,但是由于VALUE中含有emoji文字,导致执行SQL语句时报错。
1 | INSERT INTO user_info ( user_id, user_name, emoji ) |
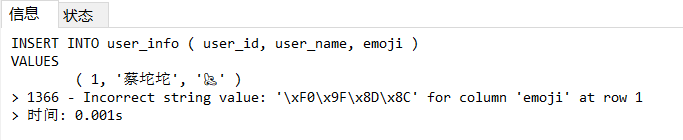
原因分析
在MySQL数据库中,utf8编码只支持每个字符最多3个字节,而真正的UTF-8每个字符最多支持4个字节。
由于emoji符号、一些较复杂的文字、繁体字、中日韩超大字符集里面的汉字都是占4个字节,所以导致写入失败。
解决方案
修改数据库编码、系统编码以及表字段的编码格式为utf8mb4:
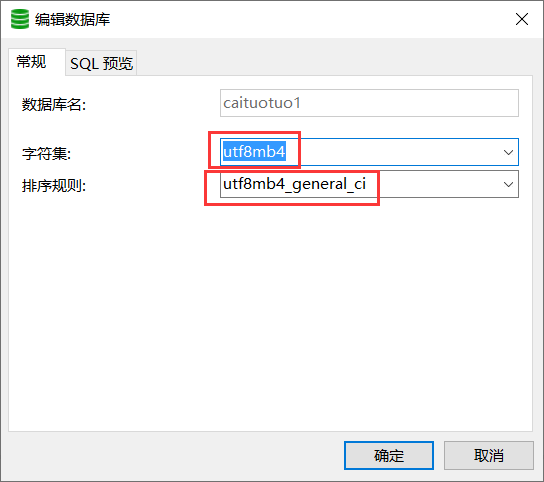
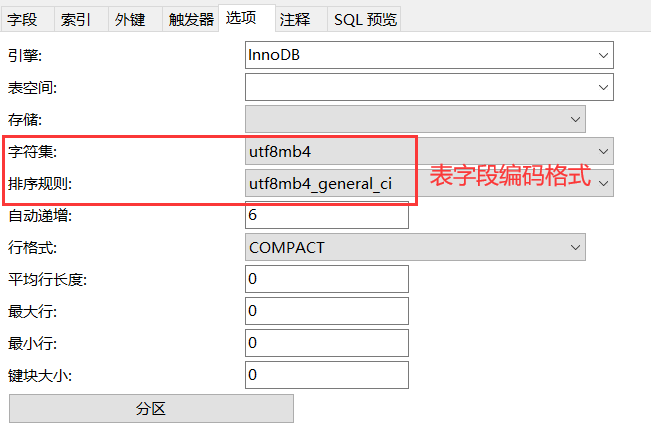
修改之后再次执行SQL语句,就可以执行成功了:
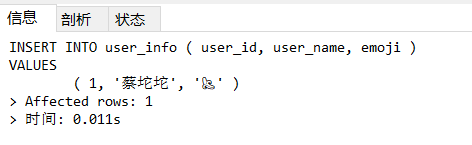
字符字节
再插入一些数据:
1 | INSERT INTO user_info ( user_id, user_name, emoji ) |
通过以下SQL语句可以清晰对比以下所占的字符数和字节数:
1 | SELECT * ,CHAR_LENGTH(emoji) as '字符' ,LENGTH(emoji) as '字节' FROM user_info; |
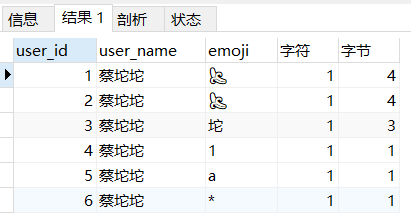
如上图所示,这是将编码改成utf8mb4之后插入的数据,其中数字、英文字母、特殊符号占1个字节,中文占3个字节,但emoji符号占4个字节,所以导致写入失败,应该改成utf8mb4。
MySQL的Bug
这个问题本质上是MySQL一直没有修复的Bug,官方在2010年发布了一个叫utf8mb4的字符集,从而巧妙地绕开这个问题。但是,他们并没有对新的字符集utf8mb4广而告之,可能是因为这个Bug让他们很尴尬,以至于很多人都还默认使用utf8,并且现在网络仍然建议开发者使用utf8,这些建议其实是错误的。
utf8mb4才是真正的UTF-8
没错,MySQL中的utf8mb4才是真正的UTF-8,MySQL中的utf8其实是一种专属的编码,它能编码的Unicode字符并不多。所有还在使用utf8编码格式的MySQL和MariaDB用户都应该改成utf8mb4,且不再使用utf8,避免出现类似的问题。
什么是编码
众所周知,计算机只认识0和1,使用0、1来存储文本的,比如:字母C会被存储为01000011,计算机在显示字母C时需要经历两个步骤,第一步计算机读取01000011,得到数字67,第二步计算机会在Unicode字符集中找到67所对应的字符C。同样,电脑会将字母C映射成Unicode字符集中的67,再将67编码成01000011发送给Web服务器。
为了方便传递信息,几乎所有的网络应用都会使用Unicode字符集,因为没有理由不使用它。
什么是UTF-8
Unicode字符集其实包含了上百万个字符,其中最简单的编码格式是UTF-32,因为每个字符都使用32位,但是这样做的缺点就是浪费空间。
在UTF-8中,字符C只需要8位,emoji符号需要32位,其他字符可能需要16位或者24位,因此UTF-8是可以变化长短的,这样做的好处就是可以更好地节省空间。
历史问题分析
为什么MySQL中的utf8不是真正的UTF-8?
或许从MySQL的更新日志中可以找到答案。
MySQL从2003年4.1版本开始支持UTF-8,而今天使用的UTF-8标准RFC3629是在此之后才出现的。
旧版的UTF-8标准RFC2279最多支持每个字符6个字节,MySQL开发者在2002年3月28日MySQL4.1预览版中使用了RFC2279标准。同年9月,官方对MySQL源码进行了调整,也就是一直沿用到现在最多支持3个字节的序列。具体为什么要这么做就不得而知了。
不过很显然,在这个不合法的字符集发布之后,MySQL就无法修复它,因为这样需要要求所有的用户重构他们的数据库,所以MySQL中utf8还是最多支持3个字节,最终,MySQL在2010年发布了utf8mb4来支持真正的UTF-8。
综上
相信很多同学还不知道这个知识点,主要是目前网络上大多数的文章教程都把MySQL中的utf8当成正真的UTF-8,因此希望看到这篇文章的小伙伴能有所收获并广而告之。所以大家以后在搭建MySQL、MariaDB数据库时,记得将数据库的编码格式设置为utf8mb4。


